Technical Description
• Methodology
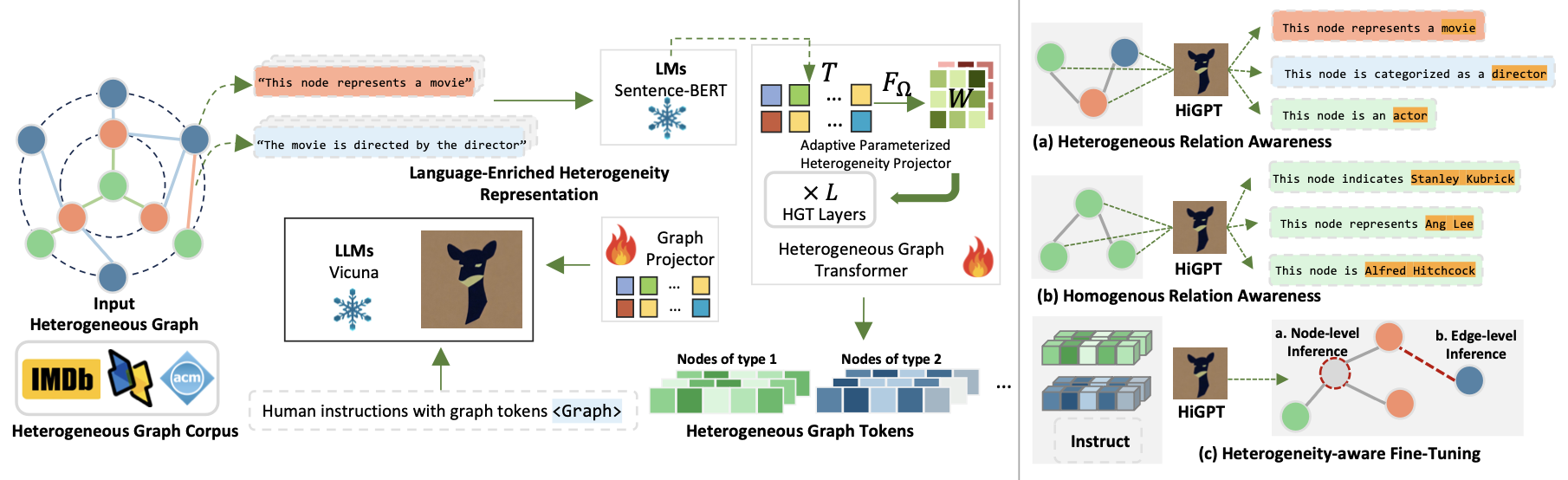
Figure 1: The overall architecture of our HiGPT.
- In-Context Heterogeneous Graph Tokenizer. To achieve adaptability in a wide range of heterogeneous graph sce- narios with varying node and edge types, we introduce the in- context heterogeneous graph tokenizer. This tokenizer captures the diverse semantic relationships found in different heterogeneous graphs, providing a unified approach. To optimize performance and integrate the tokenizer seamlessly into the HiGPT framework, we employ pre-training with a lightweight text-graph contrastive alignment paradigm.
-
Heterogeneous Graph Instruction-Tuning.
We intro- duce a novel heterogeneous graph instruction-tuning framework that integrates inter-type and intra-type token matching tasks to fine-tune large language models (LLMs). Our framework specifically targets the enhancement of LLMs' understanding of both heterogeneous relation awareness and homogeneous relation awareness. By utilizing these tasks, our aim is to bolster the LLMs' capabilities in the following areas: (i) distinguishing between different types of graph tokens, (ii) comprehending intricate relationships within heterogeneous graphs, (iii) preserving the distinctive attributes of entities within homogeneous graphs, and (iv) effectively harnessing diverse graph instructions during the training process.

Figure 2: Prompts for the three tasks of heterogeneous graph instruction-tuning.
-
Mixture-of-Thought Augmentation.
Our approach introduces a novel mechanism for augmenting graph instructions, emphasizing the use of Mixture-of-Thought (MoT) combined with various prompting techniques. This integration enables us to gen- erate a diverse and comprehensive set of informative task-specific instructions. By seamlessly incorporating these augmented graphinstructions into our framework, we anticipate that our model enhancement will effectively address the challenge of data sparsity.
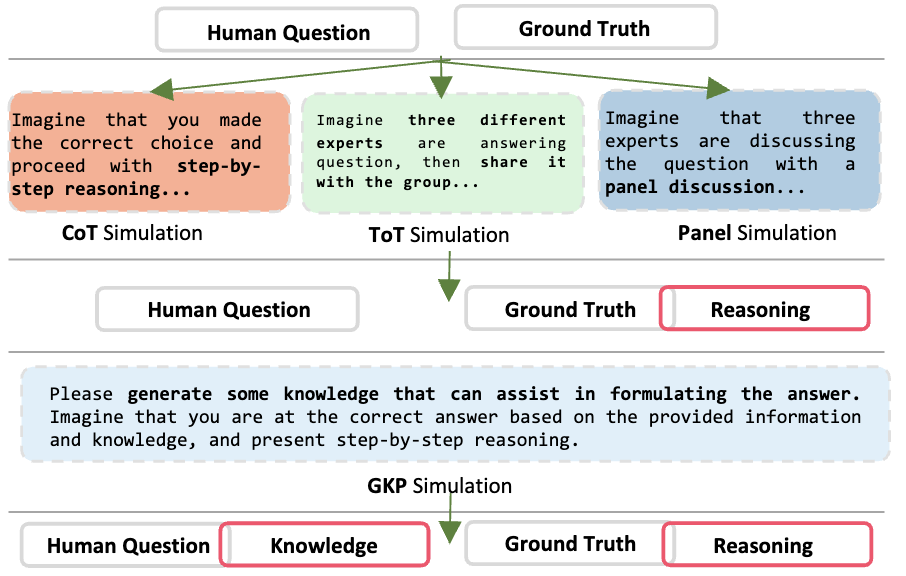
Figure 3: Mixture-of-Thought (MoT) Augmentation.
• Experiments
Overall Performance Comparison
We performed node classification tasks on three datasets, exploring both few-shot and zero-shot settings. In the few-shot settings, our model was trained on the IMDB dataset with shot numbers ranging from 1 to 60, and evaluated on the IMDB test set of 1,000 samples. For the zero-shot settings, the model was trained on the IMDB dataset with the same shot numbers, and tested on separate test sets from the DBLP and ACM datasets, each containing 1,000 samples. To enable cross-dataset transferability in supervised heterogeneous Graph Neural Networks (GNNs), we unified node and edge categories, and utilized a classifier trained with transfer data to accommodate variations in class quantities across datasets. For self-supervised methods focused on learning embeddings for downstream heterogeneous graph nodes, we excluded the zero-shot settings. The overall performance is partially shown in Table 1, with detailed results. "-std" and "-cot" notations represent the standard test prompt with direct answers and the prompt with a Chain-of-Thought (CoT) feature, respectively. These details provide insights into our node classification experiments in both supervised and zero-shot settings.
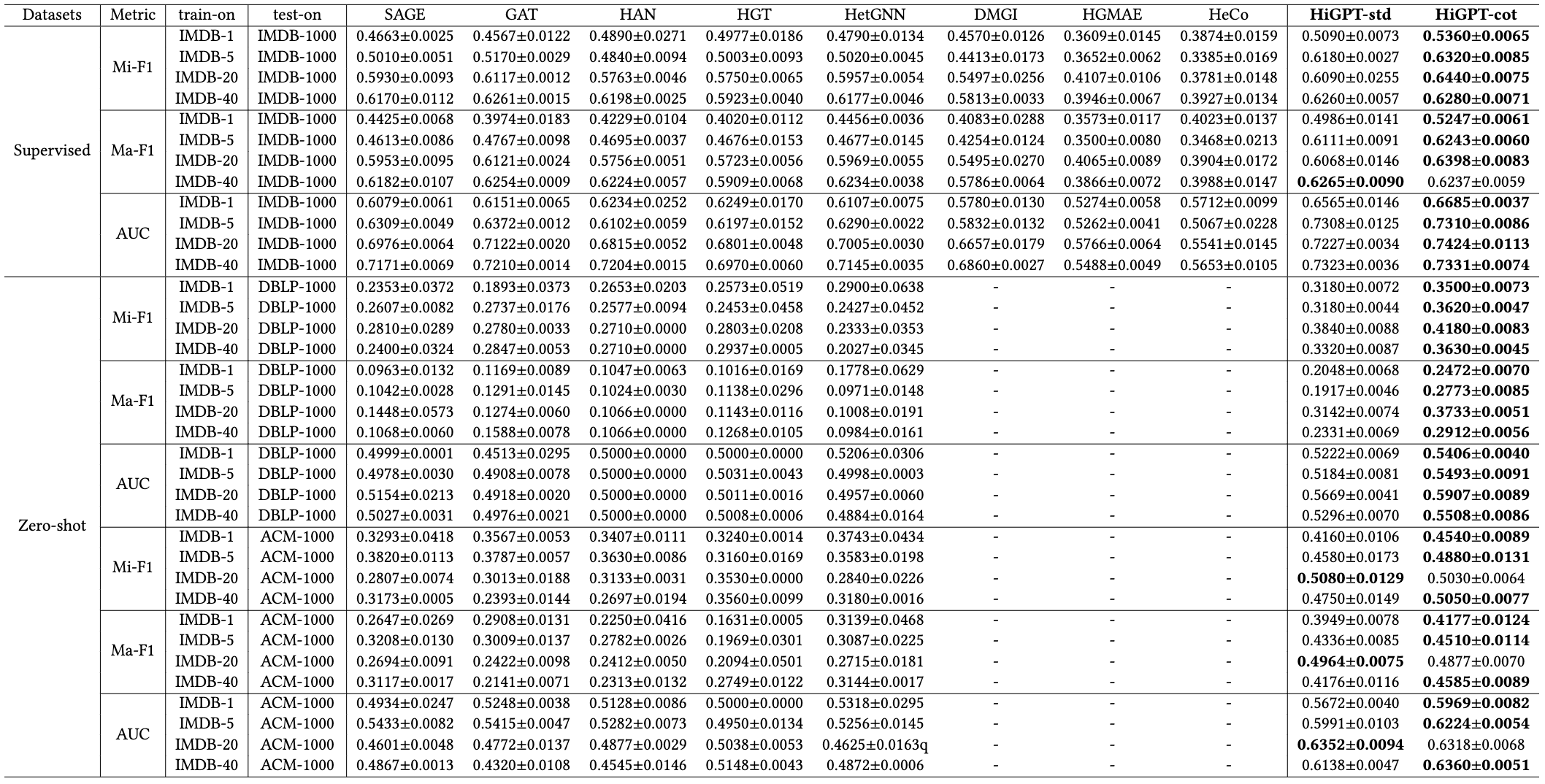
Table 1: Performance comparison on node classification tasks in both few-shot and zero-shot settings. However, since SSL methods focus on learning embeddings from downstream graphs, we excluded the zero-shot settings for them ("-").
Model Ablation Test.
To evaluate the proposed modules' effectiveness, we individually remove the key techniques in HiGPT. The results are summarized in Table 2.
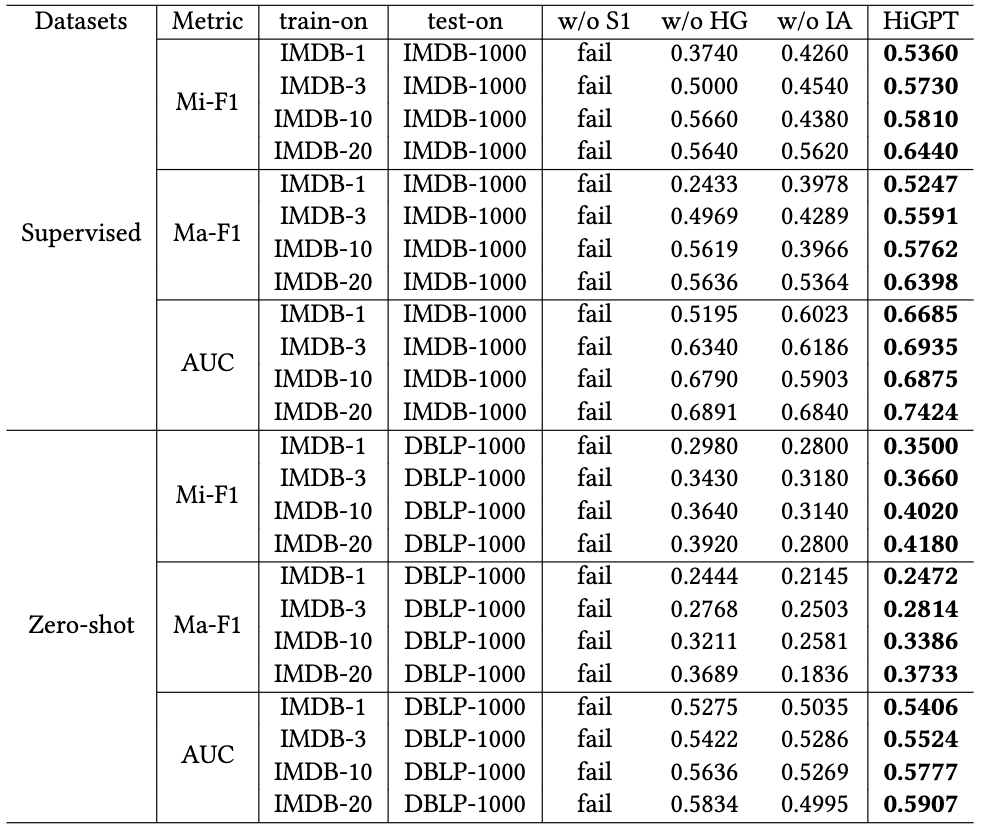
Table 2: Ablation study of our HiGPT.
Graph In-Context Learning
In-context learning (ICL) is a method for adapting large language models (LLMs) to new tasks without gradient updates, using a prompt with task examples. In this subsection, we explore the impact of Graph In-Context Learning on improving HiGPT's performance. We conduct comprehensive tests by adding prefatory examples from the training set to models trained with different shots of IMDB data. We randomly sampled training examples corresponding to the test data. "-ICL-1" and "-ICL-2" denote one and two prefatory examples, respectively. "-ICL-DBLP" signifies the inclusion of DBLP examples before the ACM test prompt. The results, depicted in Figure 5.
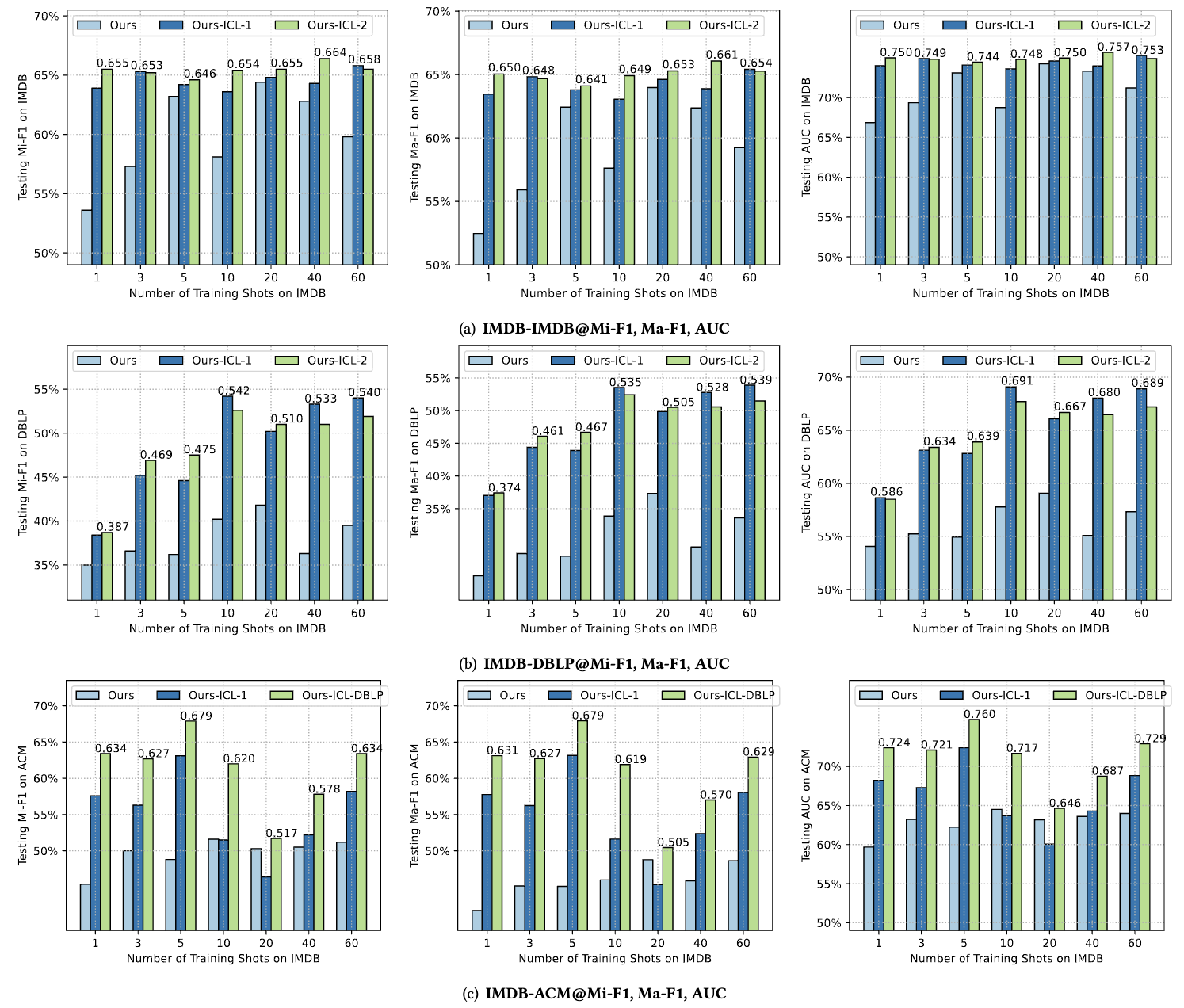
Figure 5: Comprehensive results of graph in-context learning of our HiGPT.
Case Study.
We perform a case study to showcase our HiGPT's robust generalization in understanding complex graph structures with diverse nodes and connections. Our model generates graph-aware predictions and responses, demonstrating its profound comprehension and awareness of graph-related aspects. Furthermore, we validate the positive impact of our MoT instruction augmentation.

Table 3: Visualization of our HiGPT’s response with different prompting engineering techniques on IMDB for action genre.